Highlights
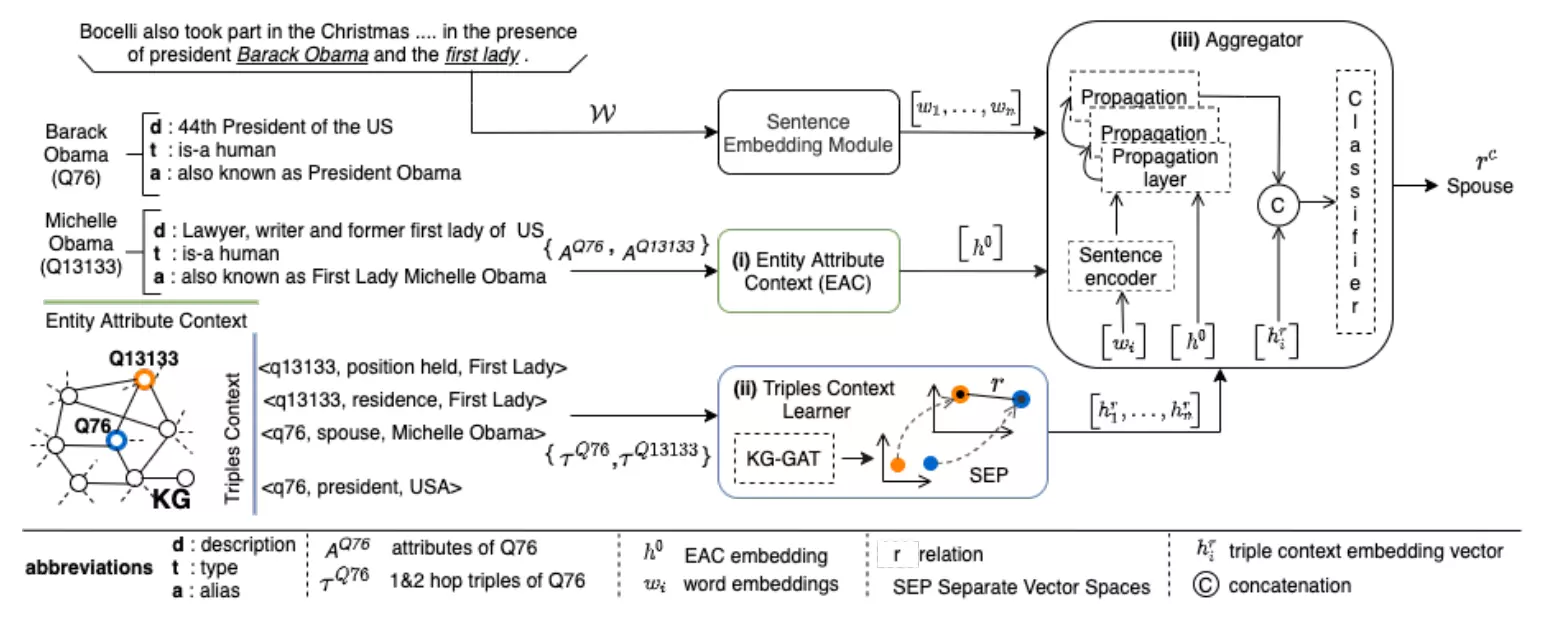
In this paper, we present a novel method named RECON, that automatically identifies relations in a sentence (sentential relation extraction) and aligns to a knowledge graph (KG). RECON uses a graph neural network to learn representations of both the sentence as well as facts stored in a KG, improving the overall extraction quality. These facts, including entity attributes (label, alias, description, instance-of) and factual triples, have not been collectively used in the state of the art methods. We evaluate the effect of various forms of representing the KG context on the performance of RECON. The empirical evaluation on two standard relation extraction datasets shows that RECON significantly outperforms all state of the art methods on NYT Freebase and Wikidata datasets.
@misc{ bastos2021recon,
title={ RECON: Relation Extraction using Knowledge Graph Context in a Graph Neural Network },
author={ Anson Bastos, Abhishek Nadgeri, Kuldeep Singh, Isaiah Onando Mulang, Saeedeh Shekarpour, Johannes Hoffart, and Manohar Kaul },
year={ 2021 }
eprint={ 2009.08694 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
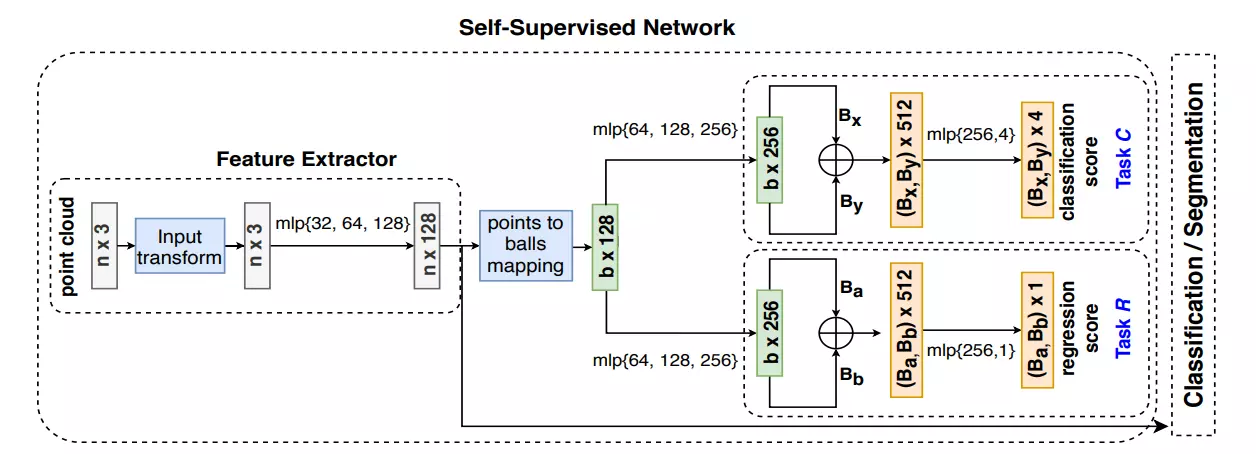
The increased availability of massive point clouds coupled with their utility in a wide variety of applications such as robotics, shape synthesis, and self-driving cars has attracted increased attention from both industry and academia. Recently, deep neural networks operating on labeled point clouds have shown promising results on supervised learning tasks like classification and segmentation. However, supervised learning leads to the cumbersome task of annotating the point clouds. To combat this problem, we propose two novel self-supervised pre-training tasks that encode a hierarchical partitioning of the point clouds using a cover-tree, where point cloud subsets lie within balls of varying radii at each level of the cover-tree. Furthermore, our self-supervised learning network is restricted to pre-train on the support set (comprising of scarce training examples) used to train the downstream network in a few-shot learning (FSL) setting. Finally, the fully-trained self-supervised network's point embeddings are used to initialize the downstream task's network. We present a comprehensive empirical evaluation of our method on both downstream classification and segmentation tasks and show that supervised methods pre-trained with our self-supervised learning method significantly improve the accuracy of state-of-the-art methods. Additionally, our method also outperforms previous unsupervised methods in downstream classification tasks.
@misc{ sharma2020selfsupervised,
title={ Self-Supervised Few-Shot Learning on Point Clouds },
author={ Charu Sharma and Manohar Kaul },
year={ 2020 }
eprint={ 2009.14168 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
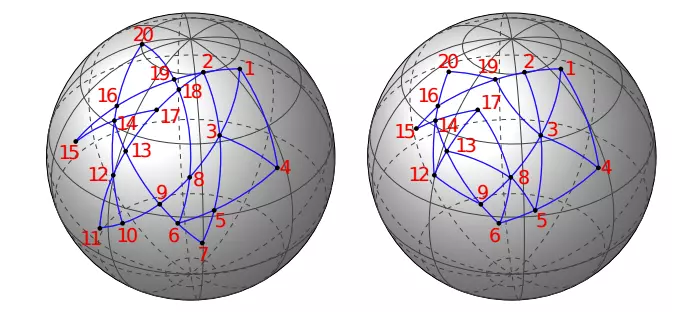
Recent increase in the availability of warped images projected onto a manifold (e.g., omnidirectional spherical images), coupled with the success of higher-order assignment methods, has sparked an interest in the search for improved higher-order matching algorithms on warped images due to projection. Although currently, several existing methods 'flatten' such 3D images to use planar graph / hypergraph matching methods, they still suffer from severe distortions and other undesired artifacts, which result in inaccurate matching. Alternatively, current planar methods cannot be trivially extended to effectively match points on images warped onto manifolds. Hence, matching on these warped images persists as a formidable challenge. In this paper, we pose the assignment problem as finding a bijective map between two graph induced simplicial complexes, which are higher-order analogues of graphs. We propose a constrained quadratic assignment problem (QAP) that matches each p-skeleton of the simplicial complexes, iterating from the highest to the lowest dimension. The accuracy and robustness of our approach are illustrated on both synthetic and real-world spherical / warped (projected) images with known ground-truth correspondences. We significantly outperform existing state-of-the-art spherical matching methods on a diverse set of datasets.
@misc{ sharma2020simplicial,
title={ Simplicial Complex based Point Correspondence between Images warped onto Manifolds },
author={ Charu Sharma and Manohar Kaul },
year={ 2020 }
eprint={ 2007.02381 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
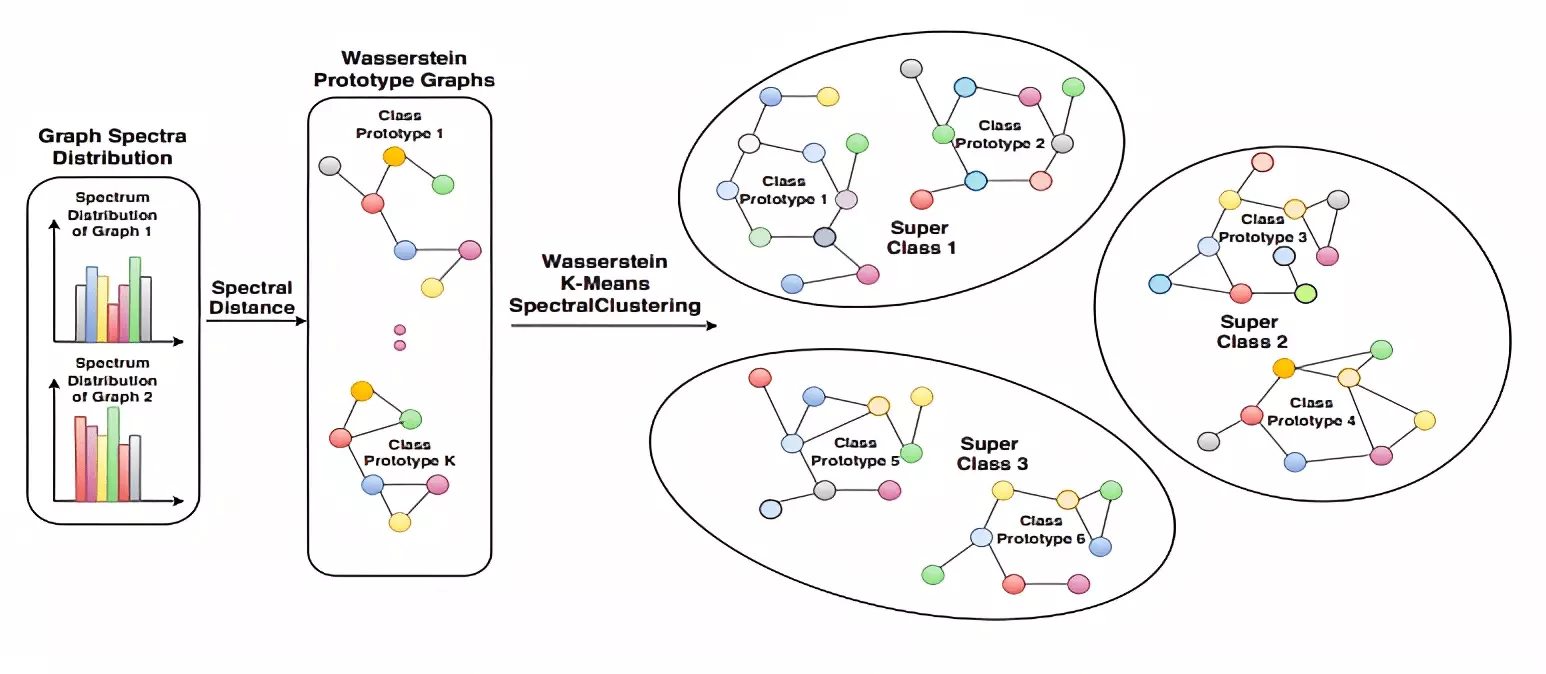
We propose to study the problem of few-shot graph classification in graph neural networks (GNNs) to recognize unseen classes, given limited labeled graph examples. Despite several interesting GNN variants being proposed recently for node and graph classification tasks, when faced with scarce labeled examples in the few-shot setting, these GNNs exhibit significant loss in classification performance. Here, we present an approach where a probability measure is assigned to each graph based on the spectrum of the graph’s normalized Laplacian. This enables us to accordingly cluster the graph base-labels associated with each graph into super-classes, where the L^p Wasserstein distance serves as our underlying distance metric. Subsequently, a super-graph constructed based on the super-classes is then fed to our proposed GNN framework which exploits the latent inter-class relationships made explicit by the super-graph to achieve better class label separation among the graphs. We conduct exhaustive empirical evaluations of our proposed method and show that it outperforms both the adaptation of state-of-the-art graph classification methods to few-shot scenario and our naive baseline GNNs. Additionally, we also extend and study the behavior of our method to semi-supervised and active learning scenarios.
@misc{ chauhan2020fewshot,
title={ Few-shot Learning on Graphs via Super-classes based on Graph Spectral Measures },
author={ Jatin Chauhan, Deepak Nathani, and Manohar Kaul },
year={ 2020 }
eprint={ 2002.12815 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
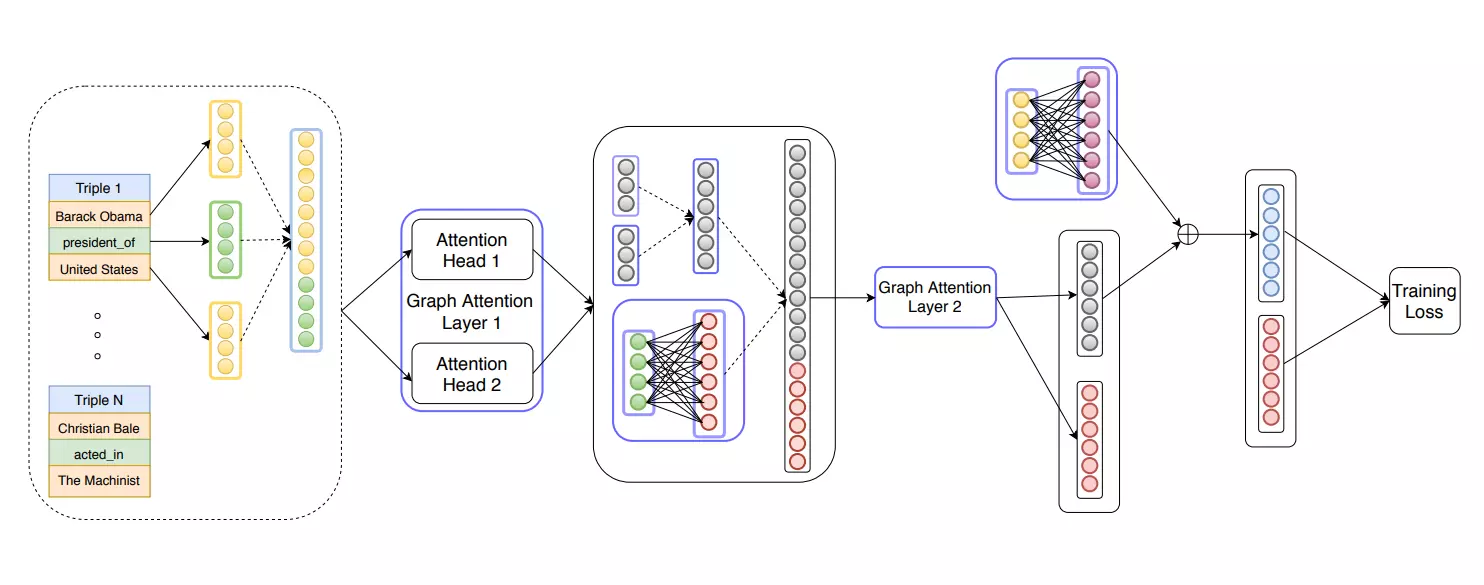
The recent proliferation of knowledge graphs (KGs) coupled with incomplete or partial information, in the form of missing relations (links) between entities, has fueled a lot of research on knowledge base completion (also known as relation prediction). Several recent works suggest that convolutional neural network (CNN) based models generate richer and more expressive feature embeddings and hence also perform well on relation prediction. However, we observe that these KG embeddings treat triples independently and thus fail to cover the complex and hidden information that is inherently implicit in the local neighborhood surrounding a triple. To this effect, our paper proposes a novel attention-based feature embedding that captures both entity and relation features in any given entity’s neighborhood. Additionally, we also encapsulate relation clusters and multi-hop relations in our model. Our empirical study offers insights into the efficacy of our attention-based model and we show marked performance gains in comparison to state-of-the-art methods on all datasets.
@misc{ nathani2019learning,
title={ Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs (long paper) },
author={ Deepak Nathani, Jatin Chauhan, Charu Sharma, and Manohar Kaul },
year={ 2019 }
eprint={ 1906.01195 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}

We present an alternate formulation of the partial assignment problem as matching random clique complexes, that are higher-order analogues of random graphs, designed to provide a set of invariants that better detect higher-order structure. The proposed method creates random clique adjacency matrices for each k-skeleton of the random clique complexes and matches them, taking into account each point as the affine combination of its geometric neighborhood. We justify our solution theoretically, by analyzing the algorithm’s runtime and storage complexity along with the asymptotic behavior of the quadratic assignment problem (QAP) that is associated with the underlying random adjacency matrices. Accuracy experiments on both synthetic and real-world datasets containing severe occlusions and distortions, demonstrate the robustness of our approach. We outperform diverse matching algorithm by a significant margin.
@misc{ sharma2020solving,
title={ Solving Partial Assignment Problems using Random Clique Complexes },
author={ Charu Sharma, Deepak Nathani, Manohar Kaul },
year={ 2018 }
eprint={ 1907.01739 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
All Publications
2021 -
Anson Bastos, Abhishek Nadgeri, Kuldeep Singh, Isaiah Onando Mulang, Saeedeh Shekarpour, Johannes Hoffart, and Manohar Kaul.
Web Conference (WWW), 2021.
Bibtex Abstract PDF
In this paper, we present a novel method named RECON, that automatically identifies relations in a sentence (sentential relation extraction) and aligns to a knowledge graph (KG). RECON uses a graph neural network to learn representations of both the sentence as well as facts stored in a KG, improving the overall extraction quality. These facts, including entity attributes (label, alias, description, instance-of) and factual triples, have not been collectively used in the state of the art methods. We evaluate the effect of various forms of representing the KG context on the performance of RECON. The empirical evaluation on two standard relation extraction datasets shows that RECON significantly outperforms all state of the art methods on NYT Freebase and Wikidata datasets.
@misc{ bastos2021recon,
title={ RECON: Relation Extraction using Knowledge Graph Context in a Graph Neural Network },
author={ Anson Bastos, Abhishek Nadgeri, Kuldeep Singh, Isaiah Onando Mulang, Saeedeh Shekarpour, Johannes Hoffart, and Manohar Kaul },
year={ 2021 }
eprint={ 2009.08694 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
2016 - 2020
Manohar Kaul and Dai Tamaki.
ArXiv.org, 2020.
Bibtex Abstract PDF
In this paper, we propose a new homological method to study weighted directed networks. Our model of such networks is a directed graph \(Q\) equipped with a weight function ww on the set \(Q_{1}\) of arrows in \(Q\). We require that the range \(W\) of our weight function is equipped with an addition or a multiplication, i.e., \(W\) is a monoid in the mathematical terminology. When \(W\) is equipped with a representation on a vector space \(M\), the standard method of homological algebra allows us to define the homology groups \(H_{*}(Q,w;M)\). It is known that when \(Q\) has no oriented cycles, \(H_{n}(Q,w;M)=0\) for \(n≥2\) and \(H_{1}(Q,w;M)\) can be easily computed. This fact allows us to define a new graph kernel for weighted directed graphs. We made two sample computations with real data and found that our method is practically applicable.
@misc{ kaul2020weighted,
title={ A Weighted Quiver Kernel using Functor Homology },
author={ Manohar Kaul and Dai Tamaki },
year={ 2020 }
eprint={ 2009.12928 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Charu Sharma and Manohar Kaul.
Neural Information Processing Systems (NeurIPS), 2020.
Bibtex Abstract Code PDF
The increased availability of massive point clouds coupled with their utility in a wide variety of applications such as robotics, shape synthesis, and self-driving cars has attracted increased attention from both industry and academia. Recently, deep neural networks operating on labeled point clouds have shown promising results on supervised learning tasks like classification and segmentation. However, supervised learning leads to the cumbersome task of annotating the point clouds. To combat this problem, we propose two novel self-supervised pre-training tasks that encode a hierarchical partitioning of the point clouds using a cover-tree, where point cloud subsets lie within balls of varying radii at each level of the cover-tree. Furthermore, our self-supervised learning network is restricted to pre-train on the support set (comprising of scarce training examples) used to train the downstream network in a few-shot learning (FSL) setting. Finally, the fully-trained self-supervised network's point embeddings are used to initialize the downstream task's network. We present a comprehensive empirical evaluation of our method on both downstream classification and segmentation tasks and show that supervised methods pre-trained with our self-supervised learning method significantly improve the accuracy of state-of-the-art methods. Additionally, our method also outperforms previous unsupervised methods in downstream classification tasks.
@misc{ sharma2020selfsupervised,
title={ Self-Supervised Few-Shot Learning on Point Clouds },
author={ Charu Sharma and Manohar Kaul },
year={ 2020 }
eprint={ 2009.14168 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Charu Sharma and Manohar Kaul.
European Conference on Computer Vision (ECCV), 2020.
Bibtex Abstract Code PDF Article
Recent increase in the availability of warped images projected onto a manifold (e.g., omnidirectional spherical images), coupled with the success of higher-order assignment methods, has sparked an interest in the search for improved higher-order matching algorithms on warped images due to projection. Although currently, several existing methods 'flatten' such 3D images to use planar graph / hypergraph matching methods, they still suffer from severe distortions and other undesired artifacts, which result in inaccurate matching. Alternatively, current planar methods cannot be trivially extended to effectively match points on images warped onto manifolds. Hence, matching on these warped images persists as a formidable challenge. In this paper, we pose the assignment problem as finding a bijective map between two graph induced simplicial complexes, which are higher-order analogues of graphs. We propose a constrained quadratic assignment problem (QAP) that matches each p-skeleton of the simplicial complexes, iterating from the highest to the lowest dimension. The accuracy and robustness of our approach are illustrated on both synthetic and real-world spherical / warped (projected) images with known ground-truth correspondences. We significantly outperform existing state-of-the-art spherical matching methods on a diverse set of datasets.
@misc{ sharma2020simplicial,
title={ Simplicial Complex based Point Correspondence between Images warped onto Manifolds },
author={ Charu Sharma and Manohar Kaul },
year={ 2020 }
eprint={ 2007.02381 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Charu Sharma, Jatin Chauhan, and Manohar Kaul.
IEEE International Joint Conference on Neural Networks (IJCNN), 2020.
Bibtex Abstract Code PDF Article
Several state-of-the-art neural graph embedding methods are based on short random walks (stochastic processes) because of their ease of computation, simplicity in capturing complex local graph properties, scalability, and interpretibility. In this work, we are interested in studying how much a probabilistic bias in this stochastic process affects the quality of the nodes picked by the process. In particular, our biased walk, with a certain probability, favors movement towards nodes whose neighborhoods bear a structural resemblance to the current node's neighborhood. We succinctly capture this neighborhood as a probability measure based on the spectrum of the node's neighborhood subgraph represented as a normalized Laplacian matrix. We propose the use of a paragraph vector model with a novel Wasserstein regularization term. We empirically evaluate our approach against several state-of-the-art node embedding techniques on a wide variety of real-world datasets and demonstrate that our proposed method significantly improves upon existing methods on both link prediction and node classification tasks.
@misc{ sharma2020learning,
title={ Learning Representations using Spectral-Biased Random Walks on Graphs },
author={ Charu Sharma, Jatin Chauhan, and Manohar Kaul },
year={ 2020 }
eprint={ 2005.09752 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Jatin Chauhan, Deepak Nathani, and Manohar Kaul.
International Conference on Learning Representations (ICLR), 2020.
Bibtex Abstract Code PDF Article
We propose to study the problem of few-shot graph classification in graph neural networks (GNNs) to recognize unseen classes, given limited labeled graph examples. Despite several interesting GNN variants being proposed recently for node and graph classification tasks, when faced with scarce labeled examples in the few-shot setting, these GNNs exhibit significant loss in classification performance. Here, we present an approach where a probability measure is assigned to each graph based on the spectrum of the graph’s normalized Laplacian. This enables us to accordingly cluster the graph base-labels associated with each graph into super-classes, where the L^p Wasserstein distance serves as our underlying distance metric. Subsequently, a super-graph constructed based on the super-classes is then fed to our proposed GNN framework which exploits the latent inter-class relationships made explicit by the super-graph to achieve better class label separation among the graphs. We conduct exhaustive empirical evaluations of our proposed method and show that it outperforms both the adaptation of state-of-the-art graph classification methods to few-shot scenario and our naive baseline GNNs. Additionally, we also extend and study the behavior of our method to semi-supervised and active learning scenarios.
@misc{ chauhan2020fewshot,
title={ Few-shot Learning on Graphs via Super-classes based on Graph Spectral Measures },
author={ Jatin Chauhan, Deepak Nathani, and Manohar Kaul },
year={ 2020 }
eprint={ 2002.12815 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Deepak Nathani, Jatin Chauhan, Charu Sharma, and Manohar Kaul.
Association for Computational Linguistics (ACL), 2019.
Bibtex Abstract Code PDF Article
The recent proliferation of knowledge graphs (KGs) coupled with incomplete or partial information, in the form of missing relations (links) between entities, has fueled a lot of research on knowledge base completion (also known as relation prediction). Several recent works suggest that convolutional neural network (CNN) based models generate richer and more expressive feature embeddings and hence also perform well on relation prediction. However, we observe that these KG embeddings treat triples independently and thus fail to cover the complex and hidden information that is inherently implicit in the local neighborhood surrounding a triple. To this effect, our paper proposes a novel attention-based feature embedding that captures both entity and relation features in any given entity’s neighborhood. Additionally, we also encapsulate relation clusters and multi-hop relations in our model. Our empirical study offers insights into the efficacy of our attention-based model and we show marked performance gains in comparison to state-of-the-art methods on all datasets.
@misc{ nathani2019learning,
title={ Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs (long paper) },
author={ Deepak Nathani, Jatin Chauhan, Charu Sharma, and Manohar Kaul },
year={ 2019 }
eprint={ 1906.01195 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Charu Sharma, Deepak Nathani, Manohar Kaul.
International Conference on Machine Learning (ICML), 2018.
Bibtex Abstract Code PDF Article
We present an alternate formulation of the partial assignment problem as matching random clique complexes, that are higher-order analogues of random graphs, designed to provide a set of invariants that better detect higher-order structure. The proposed method creates random clique adjacency matrices for each k-skeleton of the random clique complexes and matches them, taking into account each point as the affine combination of its geometric neighborhood. We justify our solution theoretically, by analyzing the algorithm’s runtime and storage complexity along with the asymptotic behavior of the quadratic assignment problem (QAP) that is associated with the underlying random adjacency matrices. Accuracy experiments on both synthetic and real-world datasets containing severe occlusions and distortions, demonstrate the robustness of our approach. We outperform diverse matching algorithm by a significant margin.
@misc{ sharma2020solving,
title={ Solving Partial Assignment Problems using Random Clique Complexes },
author={ Charu Sharma, Deepak Nathani, Manohar Kaul },
year={ 2018 }
eprint={ 1907.01739 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Chen Xu, Markus Holzemer, Manohar Kaul, Juan Soto, Volker Markl.
Transactions on Knowledge and Data Engineering (TKDE), 2017.
Bibtex Abstract PDF
Large-scale graph and machine learning analytics widely employ distributed iterative processing. Typically, these analytics are a part of a comprehensive workflow, which includes data preparation, model building, and model evaluation. General-purpose distributed dataflow frameworks execute all steps of such workflows holistically. This holistic view enables these systems to reason about and automatically optimize the entire pipeline. Here, graph and machine learning analytics are known to incur a long runtime since they require multiple passes over the data until convergence is reached. Thus, fault tolerance and a fast-recovery from any intermittent failure is critical for efficient analysis. In this paper, we propose novel fault-tolerant mechanisms for graph and machine learning analytics that run on distributed dataflow systems. We seek to reduce checkpointing costs and shorten failure recovery times. For graph processing, rather than writing checkpoints that block downstream operators, our mechanism writes checkpoints in an unblocking manner that does not break pipelined tasks. In contrast to the conventional approach for unblocking checkpointing (e.g., that manage checkpoints independently for immutable datasets), we inject the checkpoints of mutable datasets into the iterative dataflow itself. Hence, our mechanism is iteration-aware by design. This simplifies the system architecture and facilitates coordinating checkpoint creation during iterative graph processing. Moreover, we are able to rapidly rebound, via confined recovery, by exploiting the fact that log files exist locally on healthy nodes and managing to avoid a complete recomputation from scratch. In addition, we propose replica recovery for machine learning algorithms, whereby we employ a broadcast variable that enables us to quickly recover without having to introduce any checkpoints. In order to evaluate our fault tolerance strategies, we conduct both a theoretical study and empirical experimental analyses using Apache Flink and discover that they outperform blocking checkpointing and complete recovery
@misc{ oftdidp,
title={ On Fault Tolerance for Distributed Iterative Dataflow Processing },
author={ Chen Xu, Markus Holzemer, Manohar Kaul, Juan Soto, Volker Markl },
year={ 2017 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Manohar Kaul.
Conference on Innovative Data Systems Research (CIDR), 2017.
Bibtex Abstract PDF
In "The Sign of Four", Sherlock Holmes makes some very startling inferences about Watson’s whereabouts by informing Watson that he was at the Wigmore Street Post Office earlier that morning. On further inquiry by Watson, Holmes explains that he combined (joined) the observation that "Watson’s shoes had a reddish mud on their instep", with the fact that \“just opposite the Wigmore Post Office the pavement was freshly dug up to expose a similar reddish mud and it was so positioned that it would be challenging to enter the office without treading into the mud". Contrary to the popular belief that this is deduction, this method of reasoning is actually an example of abductive inference. Abduction begins from the facts observed and then seeks the simplest hypothesis (\“Occam’s razor") that best explains the facts, while deduction finds data to support a hypothesis. Given the big data challenge that we presently face, is it then possible to utilize an abductive model (effect to cause reasoning) to find the best explanation for the observations, as opposed to the traditional method of forming hypotheses and testing them with observations (cause to effect reasoning)? Can our databases extend our understanding of this data automatically by inferring explanations from incomplete observations?
@misc{ ew,
title={ Elementary, dear Watson! },
author={ Manohar Kaul },
year={ 2017 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Wikor Pronobis, Danny Panknin, Johannes Kirschnick, Vignesh Srinivasan, Wojciech Samek, Volker Markl, Manohar Kaul, Klaus-Robert Müller, Shinichi Nakajima.
ArXiv.org, 2016.
Bibtex Abstract PDF
Locality sensitive hashing (LSH) is a powerful tool for sublinear-time approximate nearest neighbor search, and a variety of hashing schemes have been proposed for different similarity measures. However, hash codes significantly depend on the similarity, which prohibits users from adjusting the similarity at query time. In this paper, we propose multiple purpose LSH (mp-LSH) which shares the hash codes for different similarities. By using vector/code augmentation and cover tree techniques, our mp-LSH supports L2, cosine, and inner product similarities, and their corresponding weighted sums, where the weights can be adjusted at query time. It also allows us to modify the importance of pre-defined groups of features. Thus, mp-LSH enables us, for example, to retrieve similar items to a query with the user preference taken into account, to find a similar material to a query with some properties (stability, utility, etc.) optimized, and to turn on or off a part of multi-modal information (brightness, color, audio, text, etc.) in image/video retrieval. We theoretically and empirically analyze the performance of three variants of mp-LSH, and demonstrate their usefulness on several real-world data sets.
@misc{ pronobis2017sharing,
title={ Sharing Hash Codes for Multiple Purposes },
author={ Wikor Pronobis, Danny Panknin, Johannes Kirschnick, Vignesh Srinivasan, Wojciech Samek, Volker Markl, Manohar Kaul, Klaus-Robert Müller, Shinichi Nakajima },
year={ 2016 }
eprint={ 1609.03219 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Larysa Visengeriyeva, Alan Akbik, Manohar Kaul.
International Conference on Information Quality (ICIQ), 2016.
Bibtex Abstract PDF
Digitally collected data suffers from many data quality issues, such as duplicate, incorrect, or incomplete data. A common approach for counteracting these issues is to formulate a set of data cleaning rules to identify and repair incorrect, duplicate and missing data. Data cleaning systems must be able to treat data quality rules holistically, to incorporate heterogeneous constraints within a single routine, and to automate data curation. We propose an approach to data cleaning based on statistical relational learning (SRL). We argue that a formalism - Markov logic - is a natural fit for modeling data quality rules. Our approach allows for the usage of probabilistic joint inference over interleaved data cleaning rules to improve data quality. Furthermore, it obliterates the need to specify the order of rule execution. We describe how data quality rules expressed as formulas in first-order logic directly translate into the predictive model in our SRL framework.
@misc{ idqlsrl,
title={ Improving Data Quality by Leveraging Statistical Relational Learning },
author={ Larysa Visengeriyeva, Alan Akbik, Manohar Kaul },
year={ 2016 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Chen Xu, Markus Holzemer, Manohar Kaul, Volker Markl.
IEEE International Conference on Data Engineering (ICDE), 2016.
Bibtex Abstract PDF
Real-world graph processing applications in many instances require combining the graph data with tabular data or making the graph processing a part of a larger analytics pipeline. General-purpose distributed dataflow frameworks typically execute such pipelines while analyzing the entire pipeline in a holistic manner to further optimize the processing. A majority of big graph processing algorithms are iterative in nature and incur a long runtime, therefore it becomes all the more necessary to tolerate and recover quickly from any intermittent failures. In this work, we propose an efficient fault-tolerance mechanism for iterative graph processing on distributed data-flow systems with the objective to reduce the checkpointing cost and failure recovery time. Rather than writing checkpoints that block downstream operators, we write checkpoints in an unblocking manner. Also, in comparison to the typical unblocking checkpointing approach of managing checkpoints independently, we inject the checkpoints into the dataflow itself. It not only inherits the advantage of a low execution latency without breaking the pipelined tasks, but simplifies the system design to coordinate the checkpoint writing. Further, we achieve speedier recovery, i.e., confined recovery, by using the local log files on each node to avoid a complete re- computation from scratch. Our theoretical studies as well as experimental analysis on Flink give further insight into our fault- tolerance strategies and show that they are more efficient than blocking checkpointing and complete recovery for iterative graph processing on dataflow systems.
@misc{ eftigpdds,
title={ Efficient Fault-tolerance for Iterative Graph Processing on Distributed Dataflow Systems },
author={ Chen Xu, Markus Holzemer, Manohar Kaul, Volker Markl },
year={ 2016 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
2011 - 2015
Manohar Kaul, Raymond Chi-Wing Wong, Christian S. Jensen.
Proceedings of Very Large Databases (PVLDB), 2015.
Bibtex Abstract PDF
The increasing availability of massive and accurate laser data enables the processing of spatial queries on terrains. As shortest-path computation, an integral element of query processing, is inherently expensive on terrains, a key approach to enabling efficient query processing is to reduce the need for exact shortest-path computation in query processing. We develop new lower and upper bounds on terrain shortest distances that are provably tighter than any existing bounds. Unlike existing bounds, the new bounds do not rely on the quality of the triangulation. We show how use of the new bounds speeds up query processing by reducing the need for exact distance computations. Speedups of of nearly an order of magnitude are demonstrated empirically for well-known spatial queries.
@misc{ nlubsdqt,
title={ New Lower and Upper Bounds for Shortest Distance Queries on Terrains },
author={ Manohar Kaul, Raymond Chi-Wing Wong, Christian S. Jensen },
year={ 2015 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Sanjay Rathee, Manohar Kaul, Arti Kashyap.
PIKM, Ph.D. student workshop at CIKM,, 2015.
Bibtex Abstract PDF
Association rule mining remains a very popular and effective method to extract meaningful information from large datasets. It tries to find possible associations between items in large transaction based datasets. In order to create these associations, frequent patterns have to be generated. The "Apriori" algorithm along with its set of improved variants, which were one of the earliest proposed frequent pattern generation algorithms still remain a preferred choice due to their ease of implementation and natural tendency to be parallelized.
While many efficient single-machine methods for Apriori exist, the massive amount of data available these days is far beyond the capacity of a single machine. Hence, there is a need to scale across multiple machines to meet the demands of this ever- growing data. MapReduce is a popular fault-tolerant framework for distributed applications. Nevertheless, heavy disk I/O at each MapReduce operation hinders the implementation of efficient iterative data mining algorithms, such as Apriori, on MapReduce platforms.
A newly proposed in-memory distributed dataflow platform called Spark overcomes the disk I/O bottlenecks in MapReduce. Therefore, Spark presents an ideal platform for distributed Apriori. However, in the implementation of Apriori, the most computationally expensive task is the generation of candidate sets having all possible pairs for singleton frequent items and comparing each pair with every transaction record. Here, we propose a new approach which dramatically reduces this computational complexity by eliminating the candidate generation step and avoiding costly comparisons.
We conduct in-depth experiments to gain insight into the effectiveness, efficiency and scalability of our approach. Our studies show that our approach outperforms the classical Apriori and state-of-the-art on Spark by many times for different datasets.
@misc{ rapriori,
title={ R-Apriori : An Efficient Apriori based Algorithm on Spark },
author={ Sanjay Rathee, Manohar Kaul, Arti Kashyap },
year={ 2015 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Qi Wang, Manohar Kaul, Cheng Long, Raymond Chi-Wing Wong.
Proceedings of Very Large Databases (PVLDB), 2014.
Bibtex Abstract PDF
Terrain data is becoming increasingly popular both in industry and in academia. Many tools have been developed for visualizing terrain data. However, we find that (1) they usually accept very few data formats of terrain data only; (2) they do not support terrain simplification well which, as will be shown, is used heavily for query processing in spatial databases; and (3) they do not provide the surface distance operator which is fundamental for many applications based on terrain data. Motivated by this, we developed a tool called Terrain-Toolkit for terrain data which accepts a comprehensive set of data formats, supports terrain simplification and provides the surface distance operator.
@misc{ ttmfttd,
title={ Terrain-Toolkit: A Multi-Functional Tool for Terrain Data (Demo) },
author={ Qi Wang, Manohar Kaul, Cheng Long, Raymond Chi-Wing Wong },
year={ 2014 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Bin Yang, Chenjuan Guo, Christian S. Jensen, Manohar Kaul.
IEEE International Conference on Data Engineering (ICDE), 2014.
Bibtex Abstract PDF
Different uses of a road network call for the consideration of different travel costs: in route planning, travel time and distance are typically considered, and green house gas (GHG) emissions are increasingly being considered. Further, costs such as travel time and GHG emissions are time-dependent and uncertain. To support such uses, we propose techniques that enable the construction of a multi-cost, time-dependent, uncertain graph (MTUG) model of a road network based on GPS data from vehicles that traversed the road network. Based on the MTUG, we define optimal routes that consider multiple costs and time-dependent uncertainty, and we propose efficient algorithms to retrieve optimal routes for a given source-destination pair and a start time. Empirical studies with three road networks in Denmark and a substantial GPS data set offer insight into the design properties of the MTUG and the efficiency of the optimal route algorithms.
@misc{ mcorputvu,
title={ Multi-Cost Optimal Route Planning Under Time-Varying Uncertainty },
author={ Bin Yang, Chenjuan Guo, Christian S. Jensen, Manohar Kaul },
year={ 2014 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Manohar Kaul, Raymond Chi-Wing Wong, Bin Yang, Christian S. Jensen.
Proceedings of Very Large Databases (PVLDB), 2014.
Bibtex Abstract PDF
With the increasing availability of terrain data, e.g., from aerial laser scans, the management of such data is attracting increasing attention in both industry and academia. In particular, spatial queries, e.g., k-nearest neighbor and reverse nearest neighbor queries, in Euclidean and spatial network spaces are being extended to terrains. Such queries all rely on an important operation, that of finding shortest surface distances. However, shortest surface distance computation is very time consuming. We propose techniques that enable efficient computation of lower and upper bounds of the shortest surface distance, which enable faster query processing by eliminating expensive distance computations. Empirical studies show that our bounds are much tighter than the best-known bounds in many cases and that they enable speedups of up to 43 times for some well-known spatial queries.
@misc{ fsptktbos,
title={ Finding Shortest Paths on Terrains by Killing Two Birds with One Stone },
author={ Manohar Kaul, Raymond Chi-Wing Wong, Bin Yang, Christian S. Jensen },
year={ 2014 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Bin Yang, Manohar Kaul, Christian S. Jensen.
Transactions on Knowledge and Data Engineering (TKDE), 2013.
Bibtex Abstract PDF
We are witnessing increasing interests in the effective use of road networks. For example, to enable effective vehicle routing, weighted-graph models of transportation networks are used, where the weight of an edge captures some cost associated with traversing the edge, e.g., greenhouse gas (GHG) emissions or travel time. It is a precondition to using a graph model for routing that all edges have weights. Weights that capture travel times and GHG emissions can be extracted from GPS trajectory data collected from the network. However, GPS trajectory data typically lack the coverage needed to assign weights to all edges. This paper formulates and addresses the problem of annotating all edges in a road network with travel cost based weights from a set of trips in the network that cover only a small fraction of the edges, each with an associated ground-truth travel cost. A general framework is proposed to solve the problem. Specifically, the problem is modeled as a regression problem and solved by minimizing a judiciously designed objective function that takes into account the topology of the road network. In particular, the use of weighted PageRank values of edges is explored for assigning appropriate weights to all edges, and the property of directional adjacency of edges is also taken into account to assign weights. Empirical studies with weights capturing travel time and GHG emissions on two road networks (Skagen, Denmark, and North Jutland, Denmark) offer insight into the design properties of the proposed techniques and offer evidence that the techniques are effective.
@misc{ yang2013using,
title={ Using Incomplete Information for Complete Weight Annotation of Road Networks },
author={ Bin Yang, Manohar Kaul, Christian S. Jensen },
year={ 2013 }
eprint={ 1308.0484 },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Manohar Kaul, Bin Yang, Christian S. Jensen.
IEEE Proceedings of International Conference on Mobile Data Management (MDM), 2013.
Bibtex Abstract PDF
The use of accurate 3D spatial network models can enable substantial improvements in vehicle routing. Notably, such models enable eco-routing, which reduces the environmental impact of transportation. We propose a novel filtering and lifting framework that augments a standard 2D spatial network model with elevation information extracted from massive aerial laser scan data and thus yields an accurate 3D model. We present a filtering technique that is capable of pruning irrelevant laser scan points in a single pass, but assumes that the 2D network fits in internal memory and that the points are appropriately sorted. We also provide an external-memory filtering technique that makes no such assumptions. During lifting, a triangulated irregular network (TIN) surface is constructed from the remaining points. The 2D network is projected onto the TIN, and a 3D network is constructed by means of interpolation. We report on a large-scale empirical study that offers insight into the accuracy, efficiency, and scalability properties of the framework.
@misc{ basnengits,
title={ Building Accurate 3D Spatial Networks to Enable Next Generation Intelligent Transportation Systems (Best Paper Award) },
author={ Manohar Kaul, Bin Yang, Christian S. Jensen },
year={ 2013 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Chenjuan Guo, Yu Ma, Bin Yang, Christian S. Jensen, Manohar Kaul.
Proceedings of ACM SIGSPATIAL GIS, 2012.
Bibtex Abstract PDF
The reduction of greenhouse gas (GHG) emissions from transportation is essential for achieving politically agreed upon emissions reduction targets that aim to combat global climate change. So-called eco-routing and eco-driving are able to substantially reduce GHG emissions caused by vehicular transportation. To enable these, it is necessary to be able to reliably quantify the emissions of vehicles as they travel in a spatial network. Thus, a number of models have been proposed that aim to quantify the emissions of a vehicle based on GPS data from the vehicle and a 3D model of the spatial network the vehicle travels in. We develop an evaluation framework, called EcoMark, for such environmental impact models. In addition, we survey all eleven state-of-the-art impact models known to us. To gain insight into the capabilities of the models and to understand the effectiveness of the EcoMark, we apply the framework to all models.
@misc{ Guo2012EcoMarkEM,
title={ EcoMark: Evaluating Models of Vehicular Environmental Impact },
author={ Chenjuan Guo, Yu Ma, Bin Yang, Christian S. Jensen, Manohar Kaul },
year={ 2012 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Gyozo Gidofalvi, Manohar Kaul, Christian Borgelt, Torben Bach Pedersen.
Proceedings of ACM SIGSPATIAL GIS, 2011.
Bibtex Abstract PDF
Emerging trends in urban mobility have accelerated the need for effective traffic prediction and management systems. The present paper proposes a novel approach to using continuously streaming moving object trajectories for traffic prediction and management. The approach continuously performs three functions for streams of moving object positions in road networks: 1) management of current evolving trajec tories, 2) incremental mining of closed frequent routes, and 3) prediction of near-future locations and densities based on 1) and 2). The approach is empirically evaluated on a large real-world data set of moving object trajectories, originating from a fleet of taxis, illustrating that detailed closed frequent routes can be efficiently discovered and used for prediction.
@misc{ frbcmoldprn,
title={ Frequent Route Based Continuous Moving Object Location and Density Prediction on Road Networks },
author={ Gyozo Gidofalvi, Manohar Kaul, Christian Borgelt, Torben Bach Pedersen },
year={ 2011 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Older
Manohar Kaul, R. Khosla, Y. Mitsukura.
Proceedings of IEEE International Symposium on Computational Intelligence in Robotics and Automation (CIRA), 2003.
Bibtex Abstract PDF
This paper proposes a traffic shaping algorithm based on neural networks, which adapts to a network over which streaming video is being transmitted. The purpose of this intelligent shaper is to eradicate traffic congestion and improve end-user video quality. It posseses the capability to predict, to a very high level of accuracy, a state of congestion based upon the training data collected about the network's behaviour.
@misc{ ipsncisvqc,
title={ Intelligent Packet Shaper to avoid Network Congestion for Improved Streaming Video Quality at Clients },
author={ Manohar Kaul, R. Khosla, Y. Mitsukura },
year={ 2003 }
eprint={ },
archivePrefix={arXiv},
primaryClass={cs.CL}
}